


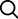







따라서 실생활에서 이용 가능하도록 더욱 똑똑한(상황에 대한 판단을 더욱 정밀하게 하는) 컴퓨터를 만들기 위해서 최대한 많은 변수를 고려하여 알고리즘을 구성해야 한다.
하지만 이 방법은 근본적인 한계가 존재한다.
세상의 모든 경우의 수를 알고리즘에 입력하는 것은 사실상 불가능하기 때문이다.
이러한 한계를 극복하고자 한 것이 바로 머신러닝(기계학습)이다. 사실 이에 대한 본격적인 연구는 1990년대 중반부터 발달하기 시작한 인터넷과 역사를 함께 한다. 인터넷의 발달과 함께 웹페이지가 생겨나면서 이곳 이 접속한 사람들이 입력하는 언어들에 대한 처리가 필요했던 것이다.
하지만 모든 단어, 문법 등을 알고리즘으로 표현해낸다고 할지라도 일상 생활에서 사용하는 비문법, 비속어 등의 모든 변수까지 입력시키기에는 한계가 존재했다.
따라서 이를 극복하기 위해 모든 변수를 알고리즘으로 입력시켜왔던 기존의 방식에 근본적인 변화가 필요했는데, 이것이 기존 알고리즘에 통계/확률의 개념을 추가한 머신러닝이다.
기존 알고리즘에 통계/확률의 개념을 추가한다는 것은 쉽게 말해서 변수를 모두 입력하는 것이 아니라, 변수에 가중치(확률)를 부여하여 예상치 못한 상황들에도 대처할 수 있도록 알고리즘을 보완한다는 의미이다. 각 변수에 부여되는 가중치로는 컴퓨터에 수많은 데이터를 input하여 도출된 가장 확률적으로 높은 결과값이 사용된다.
예를 들어 신문 기사를 자동적으로 '정치/경제/사회/문화' 등의 카테고리로 분류하는 알고리즘을 만든다고 하자. 가장 먼저 생각해 볼 수 있는 방법은 특정 단어의 사용 빈도에 따른 분류 방식의 알고리즘인데, 여기서 '특정 단어들'이 바로 X, Y 등의 변수가 되고 '사용 빈도'가 바로 가중치가 된다.
결국 알고리즘의 정확도는 어떤 가중치를 사용하는가에 달려있는데, 이를 프로그래머가 임의적으로 설정하는 것이 아니라 과거 수십년치의 신문기사를 컴퓨터에게 입력시키고(기계에게 학습을 시키고) 여기서 추출한 단어의 빈도 값(통계/확률)을 가중치로 사용하는 것이 바로 머신러닝의 기본 개념이다.
관련기사
[머신러닝①] 앨런 튜링의 3가지 조건
[머신러닝②] 인공지능 완성도, 알고리즘에 달렸다
[머신러닝④] 딥러닝, 인간의 뉴런을 모방하다
한승균 기자 / 전자공학 박사
<저작권자 © 빅데이터뉴스, 무단 전재 및 재배포 금지>






















