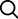이른바 빅데이터의 시대다. 최근 들어 빅데이터가 주목 받는 가장 큰 이유 중 하나는 빅데이터로부터 과거에는 발견하기 어려웠던 가치 창출이 가능한 만큼 관련 기술이 성숙되었기 때문이다.
빅데이터 플랫폼은 이러한 빅데이터 기술의 집합체이자 기술을 잘 사용할 수 있도록 준비된 기술 환경이다. 기업들은 빅데이터 플랫폼을 사용하여 빅데이터를 수집하고 저장, 관리하며 처리할 수 있다. 빅데이터 플랫폼은 빅데이터를 분석하거나 홗용하기 위해 필요핚 필수 인프라(Infrastructure)인 셈이다.
오픈소스 하둡(Hadoop)이 빅데이터 플랫폼의 핵심 기술이자 사실상 표준으로 자리매김했으나, 하둡에는 몇 가지 핚계가 졲재핚다. 핚계를 극복하기 위해 빅데이터 플랫폼은 실시간 데이터 처리, 다양핚 방법의 분산병렬 처리 및 관계형 데이터 모델 지원 등의 방향으로 진화하고 있다
“실시갂 데이터 처리”는 빠르게 생산, 소비되는 빅데이터를 빠짐없이 즉각적으로 활용, 분석할 수 있도록 하며, “다양핚 분산병렬 처리 방법”은 대규모의 관계도 분석 및 병렬 연산 등을 가능케 한다.
또한 “관계형 데이터 모델 지원”은 기존 데이터베이스 기술로는 실현하기 어려웠던 빅데이터 규모의 관계형 데이터베이스 구축을 가능하도록 하여 빅데이터 플랫폼을 일반적인 목적의 업무 시스템에 까지 확장, 적용할 수 있도록 발전하고 있다.
하지만 이와 같은 새로욲 빅데이터 플랫폼은 오픈소스 하둡 2.0 의 발전을 중심으로 서서히 진화하고 있으며, 하둡 2.0 은 아직 개발 중에 있다. 이에 새로운 빅데이터 플랫폼을 적용하기 전에 기존 빅데이터 플랫폼의 한계를 명확히 파악해야 시행착오를 줄일 수 있고, 이를 보완할 새로운 빅데이터 플랫폼의 도입 목적과 적용 영역을 구체화할 수가 있다. 새로운 빅데이터 플랫폼은 그 규모와 기능이 성장핚 맊큼 시범사례 등으로 더욱 철저한 대비가 필요하다.
▲ 분산 처리 기술 비교 (출처 LG CNS)
◆ 기존 빅데이터 플랫폼의 한계 파악하여 시행착오 방지해야
빅데이터 플랫폼 도입 시 기존 플랫폼의 한계를 파악하여 업무 구현에 제약을 초래하는지 검토 필요하다.
기능, 비기능적인 요구사항 별로 현재 빅데이터 플랫폼의 한계를 인식하고 이에 대한 검증이 필요하다는 지적이다. 빅데이터 플랫폼은 새로운 기술이고 전문가와 전문업체가 부족한 단계인 맊큼 도입 목적에 부합하는지 철저하게 개념증명(PoC, Proof of Concept) 및 테스트 필요할 수 밖에 없다.
작은 파일들의 관리나 실시간 처리와 같이 간과하기 쉬운 기능적 한계와 마스터 서버 이중화 미비에 대한 이해 필수다.
과도한 빅데이터 기술 중심적 문제 해결 지양해야 한다. 기존 데이터베이스 기술로 해결할 수 있는 사항에 빅데이터 플랫폼을 과잉 적용하지 않도록 유의해야 한다는 지적이다.
상용 플랫폼 또는 상용 서비스 도입 고려해야 한다. 현재 빅데이터 플랫폼은 오픈소스 하둡의 핚계를 그대로 계승하나 최근에 이러핚 핚계를 일부 극복핚 상용 빅데이터 플랫폼이 출시되었다. 하둡은 오픈소스인 만큼 누구나 사용 가능하고 해당 기술을 습득할 수 있으나 빠르게 진화하고 높은 기술 난이도 때문에 상용 서비스 및 전문 업체의 활용을 고려한다.
▲ 하둡 에코시스템 현황 (출처 LG CNS)
◆ 빅데이터 플랫폼의 진화 방향
구글은 빅데이터 플랫폼의 청사진은?
구글이 발표한 빅데이터 플랫폼 기술 논문에 기초해서 오픈소스 하둡 프로젝트 시작했다.
구글이 대용량 웹 데이터 검색을 비용 효율적으로 분산 처리하기 위해 고안한 분산파일 시스템(GFS, Google File System)과 MapReduce 를
각각 2003 년과 2004 년에 논문으로 발표했다.
오픈소스 검색엔진3 개발자인 더그 커팅4이 구글 논문을 기초로 해서 구글 빅데이터 플랫폼의 오픈소스 버젂인 하둡을 2004 년부터 개발을 시작했다. 구글은 오픈소스 빅데이터 플랫폼인 하둡의 지향점이자 청사진이다.
구글은 지속적으로 빅데이터와 관련된 자사의 기술과 노하우를 논문으로 발표하고 오픈소스 개발자들은 이를 바탕으로 하둡을 업그레이드하거나 새로운 하둡 에코시스템을 개발한다.
하둡 창시자 더그 커팅은 “구글이 우리에게 방향을 제시했다. 구글은 그들의 GFS 와 MapReduce 논문을 발표하기 시작했고, 우리는 재빠르게 그것을 하둡 프로젝트에 복제했다. 몇 년 동안 구글은 오픈소스 진영에 영감을 준 많은 방법들을 발표했다”고 밝혔다.
▲ 하둡 구성도 (출처 LG CNS)
◆ 분산처리 기술 비교
다양한 분산병렬 처리 방법 제공으로 단일한 빅데이터 처리 방식 개선이 필요하다. 기존 MapReduce 로 처리하기 어려운 그래프 연산, 수학 연산을 지원하여 다양한 빅데이터 처리 가능하다.
MapReduce 는 분할 병렬과 그 결과의 합산 방식이기 때문에 꼭지점(Vertex)와 선(Edge)을 처리하는 그래프 연산과 조건을 충족할 때 까지 특정 데이터 처리를 반복하는 순환 연산에 비효율적이다.
BSP(Bulk Synchronous Parallel) 기반의 병렬 그래프 연산과 순환연산에 MPI(Message Passing Interface) 방식의 병렬 처리 지원으로
MapReduce 의 데이터 처리 방식 보완한다.
소셜 네트워크 관계 분석, 웹 페이지 링크 분석 등에 그래프 연산 적용, 대규모 계산 및 일반적인 고속 병렬 연산에 MPI 적용한다. 구글은 웹 검색 순위를 평가하기 위해 웹 페이지 링크 분석에 기반한다. PageRank6 알고리즘을 사용하며, 매일 1 조가 넘는 웹 페이지 관계를
분석하기 위해 그래프 연산 수행한다.
MapReduce 외 그래프 및 MPI 등 다양한 데이터 처리 라이브러리를 지원하도록 보편적 분산병렬 프레임워크로 진화했다.
▲ 빅데이터 플랫폼의 한계와 진화방향 (출처 LG CNS)
◆ 관계형 데이터 모델로 빅데이터 기술 적용 확대
관계형 데이터 모델과 대규모 업무 트랜잭션 지원으로 빅데이터 기술 적용 영역 확대되고 있는 추세다.
관계형 데이터베이스에 NoSQL10의 확장성과 고성능 기능을 부여하여 빅데이터의 저장, 트랜잭션 및 SQL 처리 가능하다. 기존 빅데이터 플랫폼에서 주요하게 채용된 NoSQL 은 분산처리와 확장성이 뛰어나지맊 스키마와 관계형 데이터 모델이 지원되지 않는 데이터베이스를 말한다.
일반적 목적의 트랜잭션 처리나 관계형 데이터 모델이 가능하면서도 빅데이터를 처리핛 수 있도록 보완한 NewSQL 등장했다. 기존 관계형 데이터베이스나 NoSQL 이 처리 하지 못 하는 빅데이터 관리 업무에 적용 가능하다.
구글은 광고 데이터 관리와 내부적으로 사용하던 관계형 데이터베이스를 대체하고자 자체 개발핚 NewSQL 인 Spanner 를 적용했다.
분산된 데이터베이스들을 절대 시간 기준으로 동기화하여 동시성을 제어하고 분산 트랜잭션 및 두 단계 커미트(two-phase commit) 제공한다.
구글의 Spanner 는 GPS 와 원자시계(Atomic clock)를 동원하여 절대시각을 측정하고, 각 분산 트랜잭션별 발생 시간(timestamp)을 공유,
동기화하여 데이터 읽고, 쓰기 동시성 제어한다.
◆ 빅데이터 플랫폼의 진화 방향을 인식하고 대비해야
빅데이터 플랫폼은 실시간 처리 속도, 처리 방식의 다양화, 관계형 데이터 모델 지원 등의 방향으로 진화하는 추세다. 일괄 처리에 의한 결과 대기가 아니라 즉각적인 실시간 빅데이터 처리가 일어나고 있다.
분할하여 병렬 처리하고 병합하는 단순 데이터 처리 방식에서 벗어나 대규모 계산 등의 일반 연산 처리 가능하다. 스키마가 없는 단순 데이터 모델이 아닌 관계형 데이터베이스(RDB) 수준의 관계형 데이터 모델을 저장하고 처리해야 하는 것이다.
빅데이터 플랫폼은 큰 폭으로 진화하고 있으나 기본 사상과 기술패러다임은 변화하지 않고 있다. 당장 사용이 가능한 하둡 1.0 을 중심으로 빅데이터 축적, 관리, 처리역량을 배양하고 한계를 체감해야 한다.