


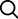







빅데이터의 대항해 시대는 병렬처리 시스템에 기반을 두고 있다. 기존의 데이터 처리는 고성능 컴퓨터를 이용했지만 빅데이터를 처리하기 위해서는 병렬처리 시스템, 흔히 클라우딩 컴퓨팅이라고 부르는 기술을 사용할 수밖에 없다.
하둡은 바로 대용량의 데이터 처리를 위해 개발된 오픈소스 소프트웨어로 하둡(hadoop)은 바로 이 클라우딩 컴퓨팅을 이용해 안정적이고 효과적으로 빅데이터를 처리할 수 있게 해준다.
하둡은 야후(Yahoo)의 재정지원으로 2006년부터 개발되었으며 현재는 아파치(Apache) 재단이 개발을 주도하고 있다.
하둡은 비싼 외부 저장장치나 데이터 웨어하우스(data warehouse)를 사용하는 것보다 오픈 소스인 하둡을 사용하는 것이 비용 절감 등에서 유리하며 설치 및 사용도 쉬운 편이라 기업에서 많이 사용하고 있다.
현재, 하둡 기술을 보유한 전문 인력이 부족하기 때문에 빅데이터를 효과적으로 활용하는 것이 매우 어렵다. 조직들은 분산 시스템 개발 및 운영의 복잡성을 이해하고 규모별로 시스템을 관리해본 경험을 가진 인력을 필요로 한다.
◆ 빅 데이터 시대의 대표 기술, 하둡
2008년 이래로 데이터 폭증 시대가 도래했다. 5년 만에 데이터 량이 44배에 이를 것으로 예측했고, 실제 이를 능가하는 수치를 기록했다. 이는 단순한 데이터량의 증가가 아니라 데이터의 다양성, 속도 등을함께 아우르는 의미다. 특히 모바일 기기나 소셜 미디어 등에서 생산되는 비정형 데이터의 증가는 소비자의 행태를 바꾸고 있으며, 이는 산업계에서는 비즈니스 경쟁의 규칙조차 바꾸고 있다.
이제 빅 데이터는 피할 수 있는 것이 아니며, 누가 먼저 빅 데이터를 활용하느냐가 향후 비즈니스를 판가름하는 척도가 된 것이다. 그러나 문제는 폭증하는 데이터를 저장, 분석, 활용하는 방법이 기존 방식으로는 거의 불가능하다는것. 특히 기존 방식이 1970~80년대 RDBMS(Relational DataBase Management System), 90년대 DW(Data Warehouse) 시대였다면, 이제 빅 데이터기술이 필요하게 된 것이다. 빅 데이터 저장 분석 기술을 대표하는 것이 바로 하둡이다.
◆ 검색에서 시작한 하둡, 클라우드 컴퓨팅과 만나 활기
하둡(Hadoop)은 지난 2005년 루센 개발자인 더그커팅과 마이크 카파렐라가 구글의 맵 리듀스 알고리즘을 구현하면서 만들어졌다. 이후 커팅은 야후로 옮겨가 검색 서비스에 하둡 기술을 적용하는 프로젝트에 참여했으며, 최종적으로는 약 4만여 대의 서버에걸쳐 하둡을 구현했다.
하둡이 널리 유명해지기 시작한 것은 클라우드 컴퓨팅과의 연계를 통해 상상을 초월하는 데이터 분석성능을 제공하는 등의 가시적인 효과가 나타났기 때문이다. 하둡 프로젝트의 핵심 설계자인 톰 화이트가 저술한 <하둡 완벽 가이드>에 따르면, 전에는 시간이 너무 오래 걸려 결과를 얻을 수 없었던 문제들을 이제는 하둡으로 빠르게 해답을 얻을 수 있게 됐다.
◆ 하둡의 대표적 구성 요소, HDFS
HDFS는 하둡의 구성 요소 가운데 가장 알기 쉽다. 이름이 뜻하는 대로 분산형 파일시스템이다.HDFS란 하둡 네트워크에 연결된 아무 기기에나 데이터를 분산해 밀어넣는 것이다.
물론 여기에도 체계가 있어 그냥 닥치는 대로 배치하는 것은 아니다. 파일을 적당한 블록 사이즈(64MB)로 나눠서 각 노드클러스터, 즉 각각의 개별 컴퓨터에 저장한다. 또한 데이터 유실의 위험이나 사람들이 많이 접속할 때의 부하 처리를 위해 각 블록의 복사본(Replication)을 만들어 둔다. 이런 형태는 RDBMS의 고도로 엄격한 저장 인프라와 비교해 보면 아무 기기에나 닥치는 대로 밀어넣는 것이나 다름없다.
◆ 하둡의 향후 과제와 발전 방향

포레스터는 최근 한 보고서에서 하둡에 대해 상대적인 미성숙, 사용 애플리케이션의 부재, 기술의 부족 등으로 인해 기업들이 문제를 겪게 될 가능성이 있다고 지적했다. 또한 하둡 전문가의 부족 등으로 시장 확대에 어려움을 겪게 될 것으로 보인다.
이에 대해 커팅은“하둡의 상대적인 미성숙은‘어린아이한테 어리다고 비난하는 것’과 같다. 하둡은 이제 걸음마를 시작했다. 다른 DBMS 기술들은 수십년간 노하우가 축적됐으며, 그동안 애플리케이션 등 많은 부분을 개선해 왔다. 하둡은 아직 이런 단계에이르지 못했다”고 반박했다.



하둡은 구글의 분산 파일 시스템(GFS) 논문 공개 후 본격적으로 개발되었는데 구글의 시스템과 대응되는 체계로 구성되어 있는 것이 그 특징이라 하겠다.
<저작권자 © 빅데이터뉴스, 무단 전재 및 재배포 금지>
헤드라인뉴스









재계뉴스
빅데이터 라이프






기업집단 빅데이터




