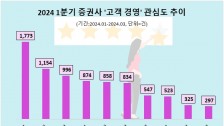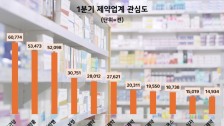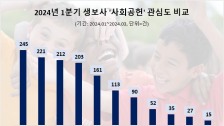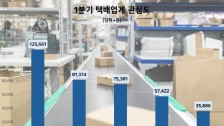








이미 빅데이터는 2016년 미국 대선에서 수많은 여론조사와 달리 트럼프 승리를 예측했고 적중시켰다. 더구나 4년 전과 비교해 구글의 국내 포털 점유율은 5% 미만에서 35% 수준까지 성장했다. 게다가 국내의 경우 지난 20대 국회의원 선거에서는 여론조사가 맞지않은 경우가 많았다.
자연스레 이번 21대 총선에서 빅데이터 분석이 여론조사를 대체할 것인지, 혹은 한물간 것처럼 보이는 여론조사를 능가할 것인지 궁금증과 관심이 많았다.
필자의 개인적 관심사를 넘어 빅데이터 분석이 이번 총선에서 판세 정확도를 높이며 존재감을 뽐낼지 초미의 전국적 관심사로 등극한 셈이다. 미국과 달리 후보자의 SNS 정보량 중에서 싫다, 나쁘다 등 ‘부정적 감성어’가 한국의 선거 지형에서는 어떻게 작용하며 어떤 결과로 나타날지 크나큰 관심사였다.
왜냐하면 당시 트럼프의 경우 SNS 정보량 가운데 싫다, 나쁘다 등 ‘부정 감성어’가 많았음에도 판세에는 영향을 주지 않은 것으로 나타났다. 이 때문에 미국처럼 ‘부정 감성어’가 한국에서도 동일하게 나타날 것인지 아니면 미국과 다른 결과로 나타날지 주목하게 된 것이다.
빅데이터에 대한 사회적 관심도를 증명이나 하듯 이번 총선에서는 다수 언론이 빅데이터 분석결과를 발표해 이목을 집중시켰다.
실제로 데일리안을 비롯한 여러 온라인 신문뿐 아니라 국민일보 등 대형 언론에서도 빅데이터 분석을 비중 있게 다뤘다. 그중에서도 한국일보는 4월 15일 4시 37분 “총선 격전지 온라인 ‘클릭’ 수치 승자는 이낙연·나경원·고민정”이라는 제목으로 후보자별 온라인 뉴스 클릭 조회 수가 높은 나경원 후보의 당선을 예측하는 보도를 냈다.
그러나 필자가 관여하는 연구소에서는 구글 트렌드의 정보량 중심 나경원 당선 예측과 다르게 이수진 후보 당선이라는 결과가 나왔다. 두 후보에 대한 정보량은 구글 트렌드와 비슷했지만 ‘부정 감성어’와 ‘긍정 감성어’에선 이수진 후보 당선이라는 예측 측이 나온 것이다.
즉, 좋다 등 ‘긍정 감성어’가 상대적으로 나경원 후보보다 높은 것에 초점을 맞춰 결과적으로는 이수진 후보의 승리를 정확하게 예측한 셈이지만 '공직선거법 108조'가 신경쓰였던 우리 연구소는 돌다리도 두들겨가는 심정으로 아주 소극적(?)으로 관망하며 애매하게 보도자료를 내놓은 탓에 아쉽게도 주목받지 못했다.
여타 빅데이터 연구소와 다른 분석결과를 어떻게 발표할지 고민하다 선거 전날 오후 4시 30분경 배포(글로벌빅데이터연구소 4월 14일 보도자료 및 글로벌빅데이터 뉴스 4월 15일 오후 4시 45분 기사 참조)했다. 결과적으로 정답을 잘 맞추고도 정작 본인은 확신 못한 꼴이어서 아쉽게도 좋은 기회를 날린 셈이다.
이후 필자가 관여하는 연구소에서는 빅데이터 해석이 왜 이렇게 서로 달랐는지 이에 대한 몇 가지 쟁점과 과제 등을 객관적으로 분석하며 확인할 필요를 느꼈다. 선거 2일 후인 4월 17일, 빅데이터 분석자료로 기반으로 활동하는 한국사회공헌포럼과 공동으로 세미나를 개최했다.
빅데이터 정보량과 선거결과를 대조하면서 검토한 결과, 미국과 다른 사실이 도출되었다. 즉 정보량이 엇비슷한 초박빙 지역의 경우 후보의 ‘부정 감성어’가 승패를 좌우한다는 것이다. 또 대선과 다르게 지역 후보를 선출하는 총선의 경우, 경계가 없는 온라인상에서 어떻게 해당 지역의 정보량인지를 구분해 읽을 것인지 풀어야 할 과제도 확인했다.
선거 막바지 여론조사를 공시할 수 없는 깜깜이 기간에 빅데이터로 추이를 보고 이에 대한 대응책을 마련하는데는 빅데이터 분석이 단연 효율적이고 가성비 높다는 사실에 이견이 없을 것이다. 다만 빅데이터 시대에 빅데이터 분석이 주목받는 만큼 더 많은 연구가 이뤄져야 한다는 사실도 부정할 수 없어 보인다.
한마디로 이번 총선에서 빅데이터 분석이 얼마나 적중했는지, 반대로 예측이 빗나갔다면 왜 그러한지는 데이터의 오류가 아니라 이 데이터가 함의하는 의미를 읽어내는 사람의 실수이거나 관점의 차이였다는 것이다.
답은 하나다. 필자를 비롯 빅데이터 연구소는 데이터에 분석 연구에 부단한 노력을 해야 한다는 사실이다.<김다솜 / 글로벌빅데이터연구소 소장>
<저작권자 © 빅데이터뉴스, 무단 전재 및 재배포 금지>